GC算法介绍
介绍 GC
GC(Garbage Collection ,
垃圾收集)是将程序运行过程中产生的一些无用的对象占用的空间进行释放,避免
OOM(Out Of Memory , 内存溢出)。
常用的GC算法有引用计数算法、标记-清除算法、复制算法、标记-整理算法
> 在 C/C++
里是由程序猿自己去申请、管理和释放内存空间,因此没有GC的概念。 > 在
Java
中,后台专门有一个专门用于垃圾回收的线程来进行监控、扫描,自动将一些无用的内存进行释放,这就是垃圾收集的一个基本思想,目的在于防止由程序猿引入的人为的内存泄露。
> 在 Python 中垃圾回收的主要算法是引用计数。
早在1960年 Lisp 就使用了 GC。 GC 主要是完成三件事情: - 哪些内存需要回收? - 什么时候回收? - 如何回收?
GC算法的评判标准主要是以下4点: 1. 吞吐量:即单位时间内的处理能力。 2. 最大暂停时间:因执行GC而暂停执行程序所需的时间。 3. 堆的使用效率:鱼与熊掌不可兼得,堆使用效率和吞吐量、最大暂停时间是不可能同时满足的。即可用的堆越大,GC运行越快;相反,想要利用有限的堆,GC花费的时间就越长。 4. 访问的局部性:在存储器的层级构造中,我们知道越是高速存取的存储器容量会越小(具体可以参看我写的存储器那篇文章)。由于程序的局部性原理,将经常用到的数据放在堆中较近的位置,可以提高程序的运行效率。
引用计数算法
引用计数法就是给每个对象一个引用计数器,每当有一个地方引用它时,计数器就会加1;当引用失效时,计数器的值就会减1;任何时刻计数器的值为0的对象就是不可能再被使用的。
这个引用计数法时没有被 Java 所使用的,但是 python 有使用到它。而且最原始的引用计数法没有用到 GC Roots。
在Python中 del 语句删除名称,而不是对象。del 命令可能会导致对象被当做垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。 > 有个
__del__特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销毁实例时,Python解释器会调用__del__方法,给实例最后的机会,释放外部资源。import weakref s1 = {1,2,3} s2 = s1 def bye(): print('Gone with the wind...') ender = weakref.finalize(s1, bye) ender.alive # True del s1 ender.alive # True s2 = 'spam' # Gone with the wind... ender.alive # False
- 可即时回收垃圾:在该方法中,每个对象始终知道自己是否有被引用,当被引用的数值为0时,对象马上可以把自己当作空闲空间链接到空闲链表。
- 最大暂停时间短。
- 没有必要沿着指针查找
- 计数器值的增减处理非常繁重,影响性能
- 计算器需要占用很多位。
- 实现繁琐。
- 循环引用无法回收
标记-清除算法
标记-清除算法是现代垃圾回收算法的思想基础。 标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。 当堆中的有效内存空间(available memory)被耗尽的时候,GC线程就会被触发并将程序暂停(stop the world),然后进行标记和清除。 - 标记:遍历所有的GC Roots,然后将所有GC Roots可达的对象标记为存活的对象。 - 清除:将遍历堆中所有的对象,将没有标记的对象全部清除掉。
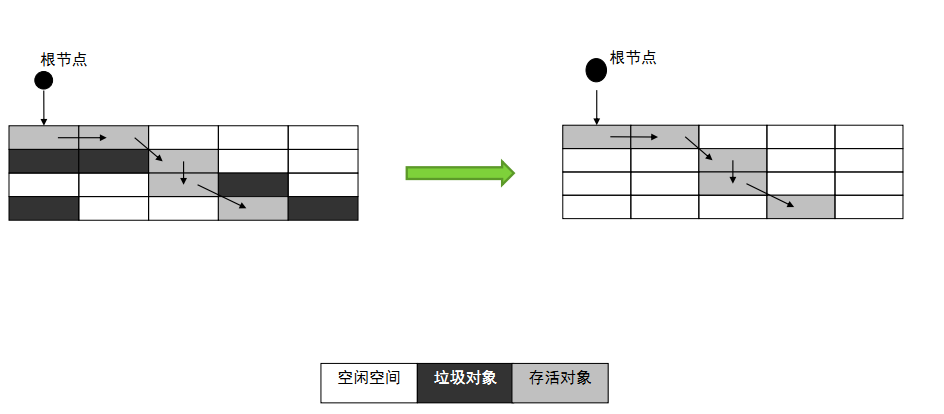
为什么非要停止程序的运行呢? 当标记结束而未开始清除时,程序又新创建一个对象,这个对象由于没有被标记,所以会被CG线程清除,从而导致错误。
- 算法简单、容易实现
- 与保守式GC 算法兼容
- 清除算法不会移动对象,所以非常适合搭配保守式算法
- 效率比较低(递归与全堆对象遍历),导致stop the world的时间比较长,导致用户体验差
- 这种方式清理出来的空闲内存是不连续的,会产生内存碎片。需要维护一个空闲列表
复制算法
复制算法(新生代的GC)是将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。
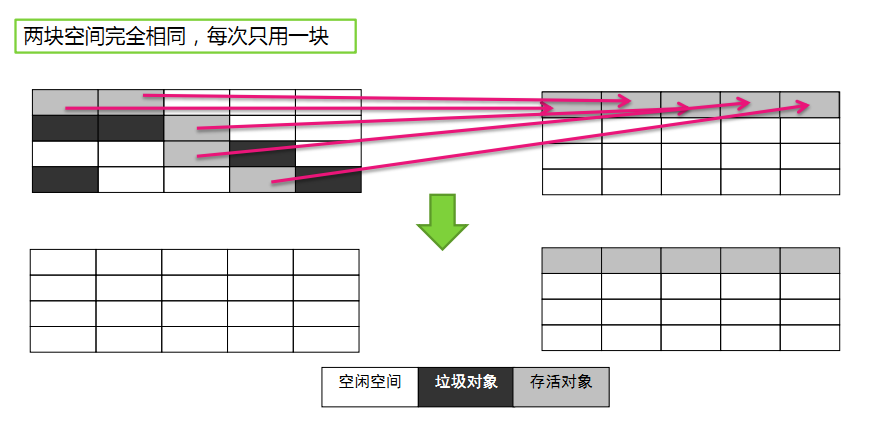 复制算法使得每次都只对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,这个太要命了。所以复制算法要想使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要克服50%内存的浪费。
现在的商业虚拟机都采用这种收集算法来回收新生代,新生代中的对象98%都是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块比较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是说,每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的空间会被浪费。
当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖于老年代进行分配担保,所以大对象直接进入老年代。整个过程如下图所示:
复制算法使得每次都只对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,这个太要命了。所以复制算法要想使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要克服50%内存的浪费。
现在的商业虚拟机都采用这种收集算法来回收新生代,新生代中的对象98%都是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块比较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是说,每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的空间会被浪费。
当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖于老年代进行分配担保,所以大对象直接进入老年代。整个过程如下图所示:
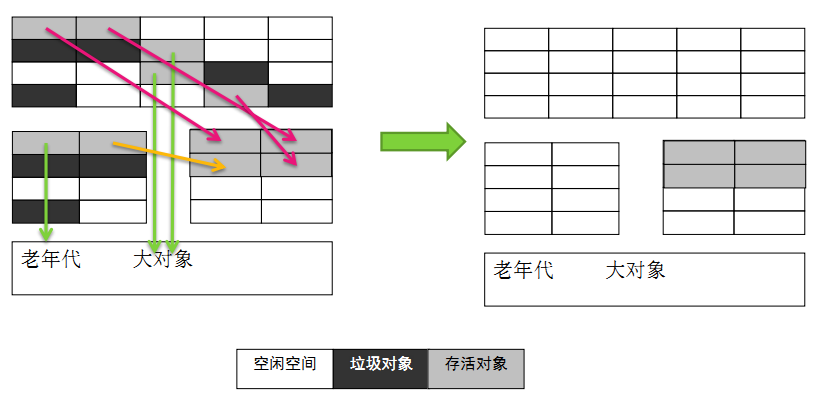 上图中,绿色箭头的位置代表的是大对象,大对象直接进入老年代。
上图中,绿色箭头的位置代表的是大对象,大对象直接进入老年代。
没有标记和清除过程,实现简单,运行高效。 复制过去以后保证空间的连续性,不会发生碎片化。 优秀的吞吐量。 可实现高速分配:复制算法不用使用空闲链表。这是因为分块是连续的内存空间,因此,调用这个分块的大小,只需要这个分块大小不小于所申请的大小,移动指针进行分配即可。 与缓存兼容。
此算法的缺点也是很明显的,就是需要两倍的内存空间。 对于G1这种分拆成大量region的GC,复制而不是移动,意味着GC需要维护region之间对象引用关系,不管是内存占用或者时间开销也不小。 堆的使用效率低下 不兼容保守式GC算法
标记-整理算法
如果在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选中这种算法。
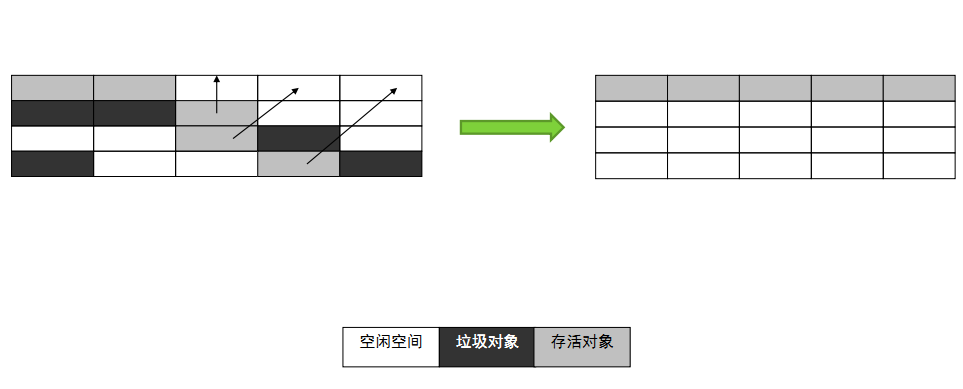
标记-压缩算法适合用于存活对象较多的场合,如老年代。它在标记-清除算法的基础上做了一些优化。和标记-清除算法一样,标记-压缩算法也首先需要从根节点开始,对所有可达对象做一次标记;但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端;之后,清理边界外所有的空间。
 -
标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC
Roots,然后将存活的对象标记。 -
整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
上图中可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
-
标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC
Roots,然后将存活的对象标记。 -
整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
上图中可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
弥补 标记/清除算法 当中内存区域分散的缺点 消除了复制算法当中内存减半的高额代价。
效率也不高。不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
小总结
效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。 内存整齐度:复制算法=标记/整理算法>标记/清除算法。 内存利用率:标记/整理算法=标记/清除算法>复制算法。 - 注1:可以看到标记/清除算法是比较落后的算法了,但是后两种算法却是在此基础上建立的。 - 注2:时间与空间不可兼得。
分代收集算法:(新生代的GC+老年代的GC)
当前商业虚拟机的GC都是采用的“分代收集算法”,这并不是什么新的思想,只是根据对象的存活周期的不同将内存划分为几块儿。一般是把Java堆分为新生代和老年代:短命对象归为新生代,长命对象归为老年代。 - 少量对象存活,适合复制算法:在新生代中,每次GC时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成GC。 - 大量对象存活,适合用标记-清理/标记-整理:在老年代中,因为对象存活率高、没有额外空间对他进行分配担保,就必须使用“标记-清理”/“标记-整理”算法进行GC。
注:老年代的对象中,有一小部分是因为在新生代回收时,老年代做担保,进来的对象;绝大部分对象是因为很多次GC都没有被回收掉而进入老年代。
保守式GC与准确式GC
保守式GC
所谓保守式GC就是“不能识别指针和非指针的GC”。 对于寄存器、调用栈、全局变量空间来说,都是不明确的根。例如调用栈中,装着函数内的局部变量和参数值。而局部变量,如C语言中的int、double这样就是非指针,但是也会有像void*这样的指针。 那么保守式GC会怎么检查不明确的根呢?1、是不是被正确对齐的值?(在32位CPU的情况下,为4的倍数)2、是不是指着堆内?3、是不是指向对象的开头?当然,这些只是基本的检查项目。 上面的检查方法会将一些非指针识别成指针。例如一个数值和一个地址,它们两个值相等,这个时候,那个值也可以被识别成指针。 保守式GC的优点是语言处理程序不依赖与GC。缺点为识别指针和非指针需要付出成本、错误识别指针会压迫堆、能够使用的GC算法有限。例如GC复制算法就不能使用,因为其可能会将非指针重写。 ### 准确式GC 准确式GC能够正确识别指针和非指针的GC。正确的根的创建方法是依赖于语言处理程序的实现的。我们可以通过打标签、不把寄存器和栈等当作根的方法来实现。 其优点就是完全能够识别指针,能够使用复制算法等需要移动对象的算法。但是在创建准确式GC时,语言处理程序必须对GC进行一些支援,而且创建正确的根就必须付出一定的代价。 其实我们垃圾回收机的实现都不是仅仅用哪一种回收算法,都是将几个结合使用,特别是分代算法,后面我们会详细的介绍。